728x90
■ AWS - S3 개요
- AWS에서 제공하는 객체 스토리지 입니다. S3에 저장되는 데이터를 "객체"라고 하며, 이 객체 저장소를 버킷 (Bucket) 이라고 합니다. 객체에 대한 입출력은 HTTP 프로토콜로 수행하며 REST API를 사용하여 명령을 전달 합니다.
■ AWS - S3 특징
- 리전 내에 최소 세 개 이상의 물리적으로 분리된 가용 영역에 데이터를 복제해서 데이터를 저장하기 때문에 높은 내구성과 고가용성을 제공 합니다.
- 서버의 OS 도움 없이 객체별 접근이 가능하므로 데이터 저장 및 활용에 용이 합니다.
- 데이터의 저장 공간이 무제한에 가까워 특별한 용량 제한 없이 데이터를 저장할 수 있습니다.
- 데이터 생애 주기에 따라 다양한 S3 스토리지 계층으로 이동 하여 비용 효율적으로 스토리지를 사용할 수 있습니다.
- S3 버킷에서 버전 관리를 활성화 화면 버전 정보가 생성 되며, 해당 정보를 통해 복구 또는 롤백을 수행 할 수 있습니다.
■ AWS - S3 구성요소
- 버킷 (Bucket): S3의 기본 컨테이너 입니다. 객체는 반드시 버킷에 저장되어야 하며, 하나의 리전에서 생성된 후 버킷 이름과 리전을 변경 할 수 없습니다.
- 버킷은 전체 리전에서 고유한 이름을 가져야 합니다.
- 버킷은 리전 수준에서 정의 됩니다.
- 버킷 이름을 지정할 때 규칙이 있습니다.
- 대문자와 언더 스코어를 사용할 수 없습니다.
- 3~36 사이 길이로 이름을 지정 할 수 있습니다.
- 이름에 IP 주소를 사용할 수 없습니다.
- 이름의 시작은 무조건 소문자나 숫자로 시작 해야 합니다.
- 이름의 시작은 xr-- 로 시작 할 수 없고, 이름의 끝은 -s3alias로 끝날 수 없습니다.
- 객체 (Object): S3에 저장되는 기본 매체로, 객체 데이터와 객체 메타데이터로 구성되어 있습니다. 객체를 저장할 때 사용자 지정 메타데이터를 지정할 수 있으며, 객체는 키(이름) 및 버전 ID를 이용하여 버킷 내에서 고유하게 식별 됩니다.
- 객체를 저장할 때 사용되는 키는 객체의 전체 경로를 나타냅니다. 그리고 키는 접두사 + 객체 이름의 조합 입니다.
- s3://my-bucket/my_folder/another_folder/my_file.txt
- my_folder/another_folder (접두사) + my_file.txt (객체 이름) 가 됩니다.
- S3는 객체 스토리지 이기 때문에 디렉토리라는 개념이 존재하지 않습니다. 평면(Flat) 구조이며 객체가 저장할 수 있는 데이터는 최대 5TB 입니다. 이처럼 다양한 크기의 데이터를 비정형 데이터 라고 하며 S3는 이런 비정형 데이터 저장에 뛰어납니다.
- 객체를 저장할 때 사용되는 키는 객체의 전체 경로를 나타냅니다. 그리고 키는 접두사 + 객체 이름의 조합 입니다.
- 키(Key): 버킷 내에서 객체의 고유한 식별자 역할을 수행 합니다. 버킷 내 모든 객체는 고유한 하나의 키를 갖게 됩니다.
- S3 데이터 일관성: 버킷에 있는 객체에 대해 여러 서버로 데이터를 복제하여 고가용성 및 내구성을 구현하고 데이터 일관성 모델을 제공 합니다.
■ AWS - S3 스토리지 계층
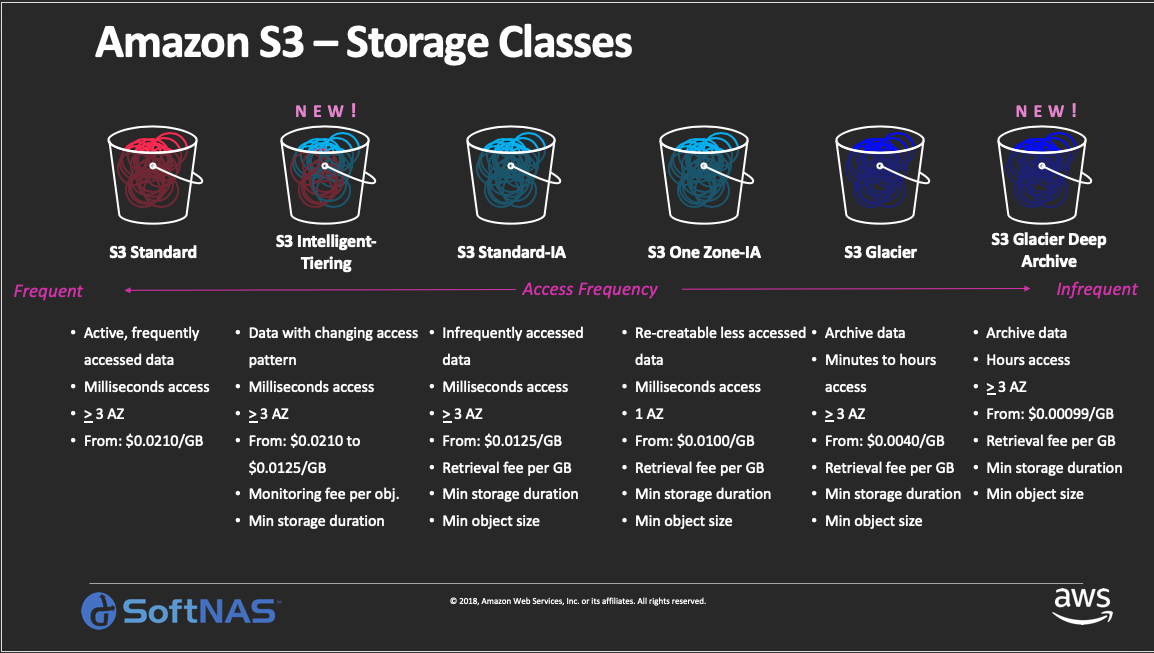
- 스토리지 클래스 지정은 객체를 업로드 할 때 또는 업로드 된 객체를 편집하여 스토리지 클래스를 변경 할 수 있습니다.
- 수명 주기 관리를 통해 특정한 시점이 지난 데이터는 다른 계층으로 이동 시킬 수 있는 정책을 세울 수 있습니다.
- Standard: 일반적인 스토리지 클래스 입니다. 데이터를 검색할 때 요금 및 최소 사용량에 제한 없이 사용한 만큼 비용을 지불 합니다.
- Intelligent-Tiering: 객체 접근 정보가 고정되어 있지 않을 때 자동으로 빈번한 접근 그룹과 건헐적 접근 그룹에 나누어서 저장 합니다.
- Standard-IA: 객체가 자주 사용되지는 않지만 조회가 필요할 때 사용되는 데이터를 저장하는 클래스 입니다. 최소 3개 이상의 가용 영역에 데이터가 저장되기 때문에 가용성이 높습니다.
- One-Zone IA: 객체가 자주 사용되지는 않지만 조회가 필요할 때 사용되는 데이터를 저장하는 클래스 입니다.하나의 가용 영역에 저장하기 때문에 상대적으로 내구성이 낮습니다.
- Glacier: 아카이브와 장기간 백업을 위한 클래스 입니다. 아카이빙 데이터에 접근 하기 위해 많은 시간이 소요되며 다른 클래스로 옮기기 위해서 기가 바이트당 비용이 발생 합니다.
- Glacier Deep Archive: 재사용이 거의 없는 데이터를 위한 클래스 입니다. 일정 시간이 지나면 삭제할 데이터를 주로 저장 합니다.

- S3 스토리지 클래스는 위 그림과 같이 다른 스토리지 클래스로 이동이 가능 합니다. 다른 스토리지 클래스로 이동을 위해서 수명 주기 사이클을 사용할 수도 있고 S3 Analyst를 이용하여 버킷에 있는 객체에 대한 정보를 .csv 파일로 받아 클래스 이동에 대한 도움을 받을 수 있습니다.
■ AWS - S3 보안
- 사용자 기반
- IAM 정책: 적절한 IAM 권한을 가진 사용자만 API 호출을 할 수 있습니다.
- 리소스 기반
- 버킷 정책: 버킷에 바로 연결되는 정책으로 다른 계정으로 부터의 요청을 허용/거부 할 수 있습니다.
- ACL (Access Control List): 객체 수준에서 누가 무엇을 하는지 상세하게 정의하는 것 입니다.
- 암호화
- Server Side Encryption (SSE-S3) - S3에서 관리하는 키를 이용한 서버측 암호화 (기본값)
▪ AWS에서 관리되는 키 이며 사용자는 해당 키에 접근 할 수 없음.
▪ AES-256 암호화 방식 사용
▪ 헤더에 "x-amz-server-side-encryption":"AES256A" 삽입
▪ 해당 암호화 방식은 신규 버킷이나 객체에 기본적으로 활성화되는 기본값 - Server Side Encryption (SSE-KMS) - KMS키를 이용한 암호화
▪ KMS 키 관리 서비스를 이용하여 사용자가 키를 생성 및 관리 수행 및 객체 암호화 수행
▪ Cloud Trail을 통해 키 사용을 검사 가능
▪ 헤더에 "x-amz-server-side-encryption":"aws:kms" 삽입
▪ 저장된 객체를 활용하기 위해 객체 엑서스 + KMS 키 엑서스가 가능해야 하므로, 보안성 강화 효과를 얻을 수 있음.
▪ 리전에 따라 초당 KMS를 호출 할 수 있는 임계점이 있고, Service Quota 콘솔을 이용하여 해당 임계점을 조절 할 수 있음 - Server Side Encryption (SSE-C) - 고객이 제공한 키를 이용한 암호화
▪ 고객이 제공하는 키를 사용하여 Server Side 암호화를 수행하며, 해당 키는 S3에 저장되지 않음
▪ HTTPS를 사용해야 하고, 암호화 키가 HTTP 헤더에 포함되어 제공되어야 함 - Client Side Encryption - 고객이 직접 데이터를 암호화 하고 S3에 전송
▪ Amazon S3 Client Side Encryption Library를 사용하여 고객이 직접 데이터 암호화 수행 - Encryption in Transit (SSL/TLS) - 전송 되는 데이터 암호화
▪ S3는 HTTP/HTTPS 2개의 Endpoint Service를 제공하며 전송중 암호화가 제공되는 HTTPS 사용 권고
▪ SSE-C 매커니즘을 사용할 경우 반드시 HTTPS 사용 필수
▪ 버킷 정책을 이용하여 HTTPS 사용을 강제 할 수 있음
- Server Side Encryption (SSE-S3) - S3에서 관리하는 키를 이용한 서버측 암호화 (기본값)
■ AWS - S3 Bucket 정책
- JSON 기반으로 정책이 생성되며 생성 된 정책은 S3 버킷에 적용 됩니다.
- 정책 생성은 정책 생성기를 활용하며 S3 >> 버킷 >> 버킷_이름 >> 권한 탭 >> 버킷 정책 으로 이동하고 정책 편집을 통해 필요한 정책을 생성할 수 있습니다. 정책을 생성할 때는 정책 생성기를 활용 합니다.

- 정책 타입 지정: S3 Bucket
- Effect : 허용 / 거부 결정
- Principal: 적용 대상. * 를 입력할 경우 적용 대상이 전체가 됩니다.
- AWS Service: 정책 타입 지정 상속
- Action: 수행할 행위 지정. S3에 있는 데이터를 보고 싶을 경우 GetObject 선택
- ARN: 자신의 S3 ARN 정보 입력 + /* (/는 ARN 경로 이후에 대해서 *는 전체 경로 대한 지정)
■ AWS - S3 복제
- S3 버킷의 데이터를 복제하기 위해서 원본과 대상 버킷에 버전을 활성화 해야 합니다.
- 데이터 복제는 비동기 방식으로 수행되고 동일 리전 복제 (Same Region Replication, SRR)과 다른 리전 복제 (Cross Region Replication, CRR)이 있습니다.
- 복제를 수행하기 위해 적절한 IAM 권한이 필요 합니다.
- CRR 사용 사례: 저지연 접속, 다른 계정으로 복제, 컴플라이언스 준수가 있습니다.
- SRR 사용 사례: 로그 집계, 상용 데이터를 테스트로 이관하여 분석하기 위함이 있습니다.
■ AWS - S3 Access Logs
- 감사 목적으로 S3 버킷에 대한 모든 접근을 로그로 남길 수 있습니다. 모든 접근의 의미는 S3 버킷에 접근하는 모든 계정, 허용, 거부 및 인가 상태를 의미 합니다.
- Access Log는 동일 리전의 다른 S3 버킷에 저장되며, Athena와 같은 Serverless SQL을 사용하여 데이터를 분석 할 수 있습니다.
- 서비스 버킷을 Access Log가 저장되는 로깅 버킷으로 설정 하면 안됩니다. 로깅 루프가 생겨 비용 및 불필요한 데이터가 급증하게 됩니다.
■ AWS - S3 객체 보존 (Glacier Vault, S3 Object Lock)
- S3 Glacier Vault Lock
- WORM (Write Once Read Many) 모델 사용
- Vault 잠금 정책을 생성하고 적용한 후에는 변경 수정이 불가능 합니다.
- 규정 준수와 데이터 보존과 같은 법률적인 사항을 따라야 할 때 유용 합니다.
- S3 Object Lock (Versioning 필수 적용)
- WORM (Write Once Read Many) 모델 사용
- 버킷 전체에 적용되지 않고, 버킷 내 모든 객체에 각각 적용할 수 있습니다. 정책이 적용되는 기간 동안 해당 객체는 삭제가 불가능 합니다.
- Retention Mode - Compliance
▪ Glacier Vault Lock과 유사 합니다.
▪ ROOT 사용자를 포함한 어떤 사용자도 객체를 덮어 쓰거나 삭제 할 수 없습니다.
▪ 객체 보존 모드는 변경이 불가능 하고, 보존 기간을 짧게 수정 할 수 없습니다. - Retention Mode - Governance
▪ 일반적인 사용자는 덮어쓰기나 삭제 또는 잠금 설정을 변경 할 수 없습니다.
▪ IAM을 통해 특별한 권한을 부여 받은 사용자는 보존 기간 변경 및 객체 삭제를 수행 할 수 있습니다. - Legal Hold (법적 보존)
▪ 보존 기한과 별개로 객체를 영구적으로 보호 합니다
▪ S3:PutObjectLegalHold IAM 권한을 사용하여 어떤 객체든 법적 보존을 설정하거나 제거 할 수 있습니다.
728x90
'AWS' 카테고리의 다른 글
| AWS - CloudFormation (실습) (0) | 2024.03.07 |
|---|---|
| AWS - CloudFormation (1) | 2024.03.07 |
| AWS - Elastic File Storage (EFS) (0) | 2024.03.02 |
| AWS - Elastic Block Storage (EBS) (0) | 2024.03.02 |
| AWS - EC2 Auto Scaling 구축 (실습) (0) | 2024.03.01 |

